An Introduction To Machine Learning Ops
As the tidal wave of AI continues to surge with companies such as OpenAI releasing more sophisticated iterations of their products, practices such as MLOps are becoming all the more relevant in the modern landscape of cloud infrastructure.
Inspired by DevOps, Machine Learning Ops or Deep Learning Ops is the practice and methodologies surrounding the creation of machine learning models, the iteration and training of these models in addition to the curation of automatable workflows that allow these models to be deployed or utilised within Production environments.
This post aims to give an overview on what MLOps is and the key areas involved in understanding how we create an automatable, scalable workflow for the consistent delivery of performant models.
The Life Cycle
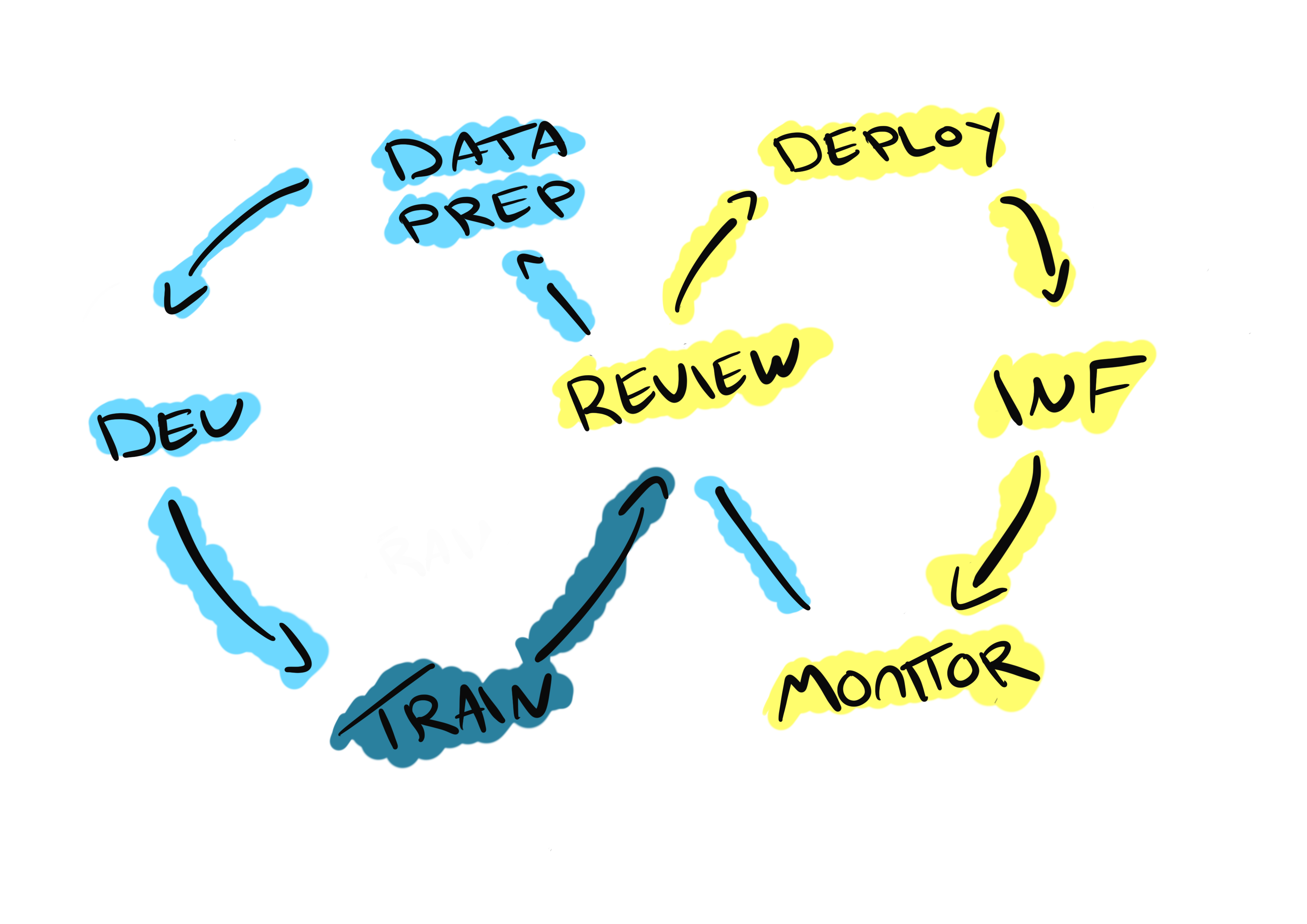
As above, the life cycle of Machine Learning is a constant iteration of data ingestion, data preparation, model training and tuning, model deployment, model monitoring, prediction and inference. Each of these areas can be considred their own specialism with their own individual challenges, we’ll dicuss some at a high level in this post and will delve into each in further detail in posts that follow.
The purpose of MLOps?
What once began as a set of best practices to help improve the workflows between Data Science and DevOps teams, MLOps has now evolved into a vast practice in which we are now seeing the introduction of frameworks solely aimed at managing the development and deployment of models in an automatable and iteratable fashion.
Two examples of these frameworks are:
MLFlow is an open source platform to manage the ML lifecycle, including experinmentation, reproducibility, deployment, and a central model registy.
The Kubeflow project is dedicated to making deployments of machine learning (ML) workflows on Kubernetes simple, portable and scalable.
DevOps vs MLOps
As the benefits of DevOps and agile methodologies has been very apparant over the previous years, it makes sense that the emerging technologies continue to follow the methodology of defining a baseline set of best practices that involves automation and continuous integration.
MLOps is no different and does indeed follow this approach. However, there are some key differences when it comes to comparing DevOps and MLOps:
-
MLOps is experimental at a core level - the models themselves are constantly undergoing changes to gain better performance. This is not a consistent release of a new version of a code base like we are used to, but rather a constant tweaking of features and state to observe how the outcome, in this case the outputted data / prediction set changes.
-
Hybrid Teams - Teams now have a requirement for data scientists and data researchers who are responsible for the analysis and research of data used in the model and throughout the workflow.
-
Continuous Testing - In addition to the familiar tests we see in a DevOps pipeline, such as unit tests and integration tests, the MLOps pipeline must continously test the model itself to ensure it’s accuracy is maintained.
-
Automatic Retraining - For the model to remain performant, it requires constant tuning and training. This will rely heavily on automation as otherwirse it will be an incredibly time consuming task and slow down the pace of model development dramatically.
-
Performance Deg and Data Monitoring - We’re no longer just looking for errors and outages. Everything encompassing the model could be working as expected but the quality of data / predictions outputted by the model is at risk of dropping due to a number of varying factors. Monitoring this quality and minimising the risk imposed by these factors presents a whole new set of challenges for enginering teams.
The application of MLOps?
The most common application of MLOps practices will be within Data Science projects. Although we are seeing machine learning become a staple of modern infrastructure in the current world, solely data driven projects will continue to be the best example of how MLOps is deployed at scale. To better understand the implementation, we can look at the lifecycle of a data science project.
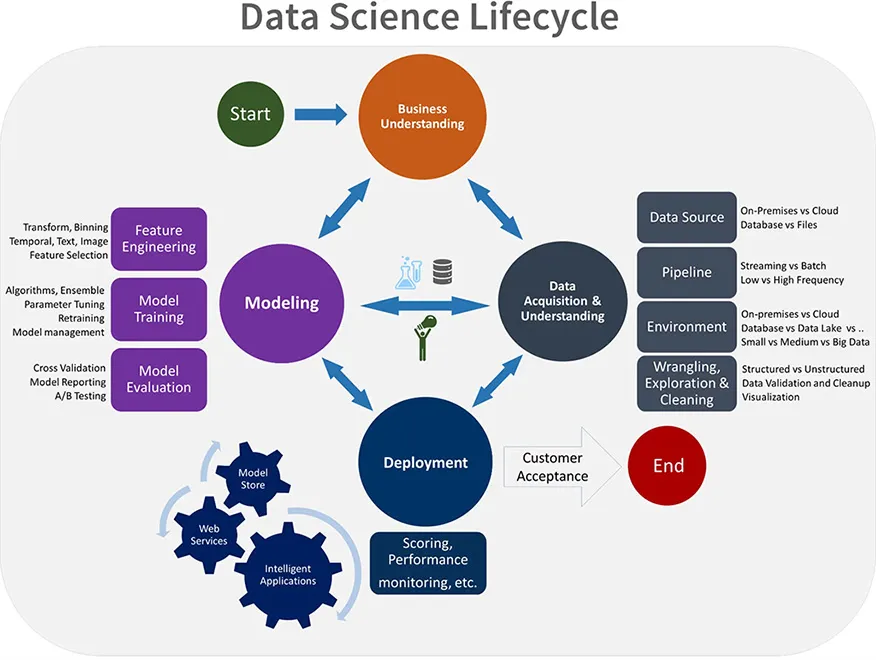
Much like DevOPs, MLOPs is not only focused on the management of the technologies and data involed in machine learning, but also what infrastructure components and practices are required to support and maximise efficiency between the teams involved at each step of the process. The Team Data Science Process lifecycle provides a clear lifecycle that we can use to structure data-science projects and is comprised of the below 5 stages:
- Business Understanding.
- Specify the key variables that are to serve as the model targets and whose related metrics are used to determine the success of the project.
- Identify the relevant data sources that the business has access to or needs to obtain.
- Data Acquisition and Understanding.
- Produce a clean, high-quality data set whose relationship to the target variables is understood. Locate the data set in the appropriate analytics environments so you are ready to model.
- Develop a solution architecture of the data pipeline that refreshes and scores the data regularly.
- Modelling.
- Determine the optimal data features for the machine-learning model.
- Create an informative machine-learning model that predicts the target most accurately.
- Create a machine-learning model that’s suitable for production.
- Deployment.
- Deploy models with a data pipeline to a production environment for final user acceptance.
- Customer Acceptance.
- Confirm that the pipeline, the model, and their deployment in a production environment satisfy the customer’s needs.
What should MLOps Infrastructure be capable of?
With the TDSP in mind we can start to answer the question of what is machine learning infrastructure and how do we ensure its effectiveness?
Infrastructure that encompases machine learning includes the resources, processes and tooling that is required to develop, train and operate machine learning models in a way that is both scalable and contributes to the accuracey of the model. Each stage of the machine learning workflow should be supported by components that allow for a high pace of model development and delivery to be maintained, in it’s linear form, the workflow looks as below:
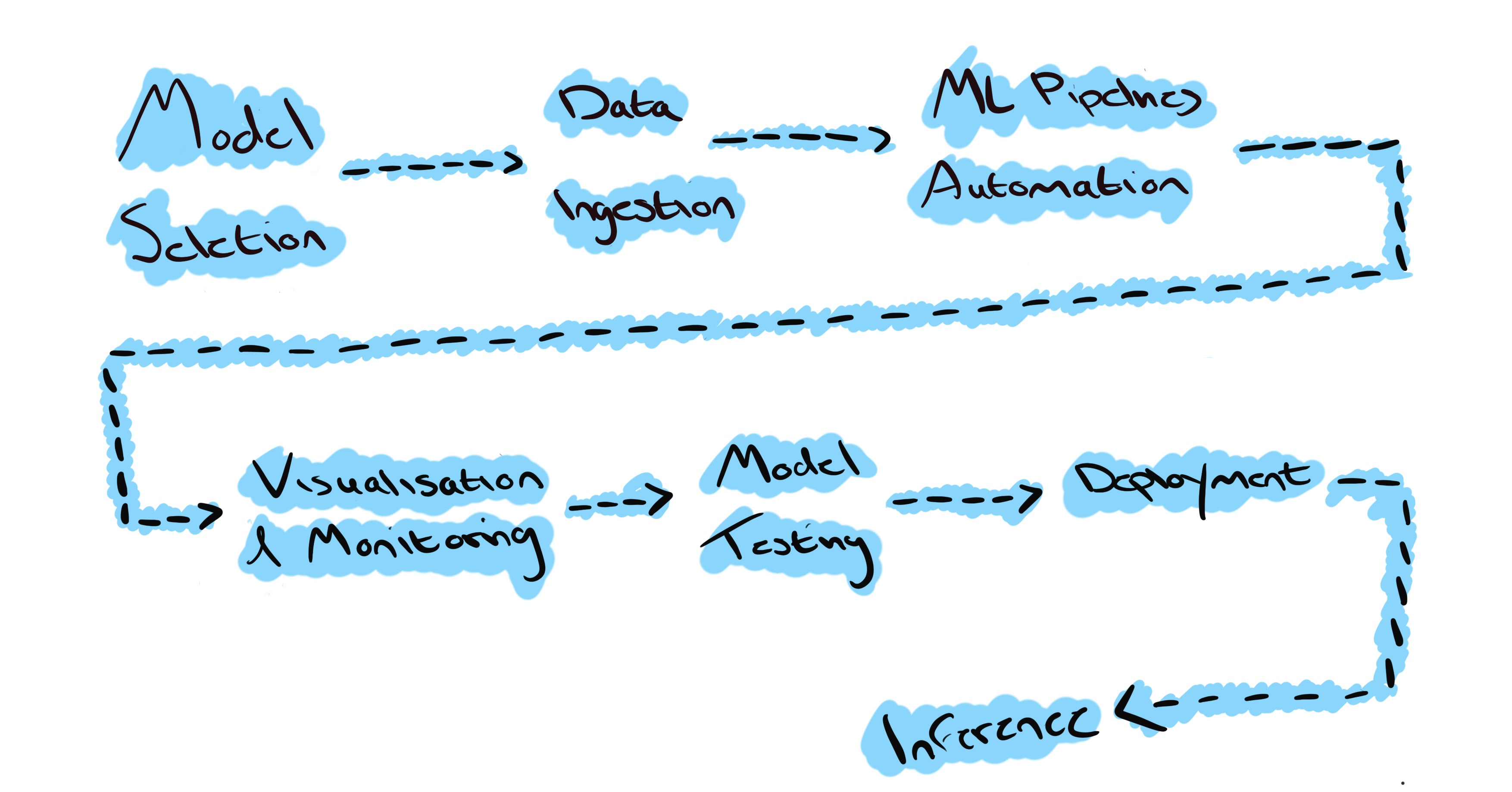
To understand what is required of the infrastructure, it is first important to have an understanding of each stage of the ML workflow.
Model Selection
Simple and straight forward enough, the model selection process involves the selection of a model that is best suited to the stakeholders requirements. There are a number of considerations which should drive the model selection process, for example:
-
Performance - The quality of predictions / results the model is capable of producing.
-
Explainability - Being able to understand the model and interpret its output.
-
Dataset Size - How large of a dataset / sample set is required for the model to remain performant?
-
Dimensionality - The number of input variables or features that the model requires.
-
Training Time and Cost - How long will it take for stakeholders to become skilled with the model and what are the other associated costs with its adoption?
-
Inference Time - The amount of time the model requires to make predictions on new data.
Data Ingestion
Data injestion is one of the core pillars of any machine learning workflow. The components that collect data within ML infrastructure needs to collect data for the training of the model, refine the data so that it’s usable or enriched and apply the data sets in a logical sense.
This requires connections to various data sources, data processing and delivery pipelines, and storage solutions. These tools need to be both scalable and highly performant. You’ll more than likely have heard the terms ELT (Extract, Load, Transform) Pipelines and Data Lake. These are often the types of tools that will be used in data ingestion methodologies across machine learning approaches.
Pipelines and Automation
The modern Operations stack has a cemented set of tools for CI/CD approaches, the most commonly used today being Azure DevOps and GitHub Actions. We’ll not delve too deep into the semantics of CI/CD in this post, but the crux of it is these pipelines will be responsibile for mediating the collection and delivery of data sets, the initiation and monitoring of model training and ultimately the deployment of new models to production environments.
Visualisation and Monitoring
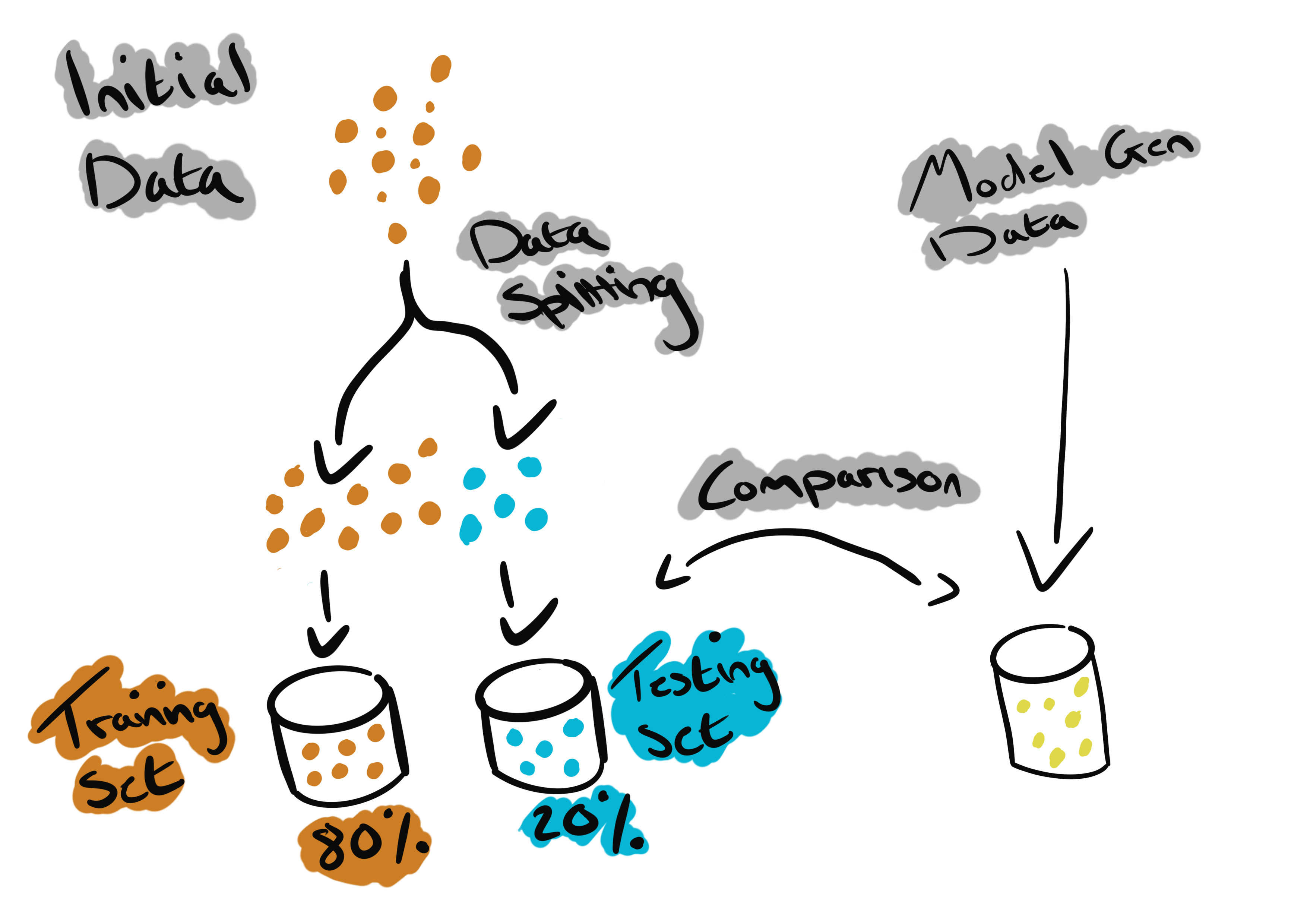
The monitoring principles that are applied to common modern infrastructure solutions do not differ much from those that are applied to Machine Learning workflows. We have a set of pre-defined metrics and we gain understanding and insight regarding how our infrastructure and models are performing. The difference when monitoring a machine learning model is the metrics, we’re no longer just looking for CPU and Memory data. Instead we’ll have a set of bounds that define the % of accruacy at which our model is making predicitions based on the current data. The how of this will be covered in future posts but in short, we monitor prediction accuracy by splitting our initial data set into two subsets. A training set comprised of 80% of the initial data which we will use to train the model, and a testing set comprised of 20% of the initial data. We will then create an additional set of testing data via prediction from our trained model and compare this with the initial testing set.
As a side note, there are a lot of finer aspects of monitoring when it comes to maintaining the accuracy of a model. As an example, Data Drift is one of the primary reasons that the accuracy of machine learning models degrade over time. Data drift is defined as any change in input data or the data ingestion process that sees a negative impact on the models performance. We’ll look at data drift in further detail in future posts but if you would like to read more, Azure has documentation which provides a good overview in addition to outlining some of the current tools for tackling it.
Model Testing
The testing of machine learning models within an infrastructure estate requires the integration of tooling between the training and deployment stages. As above, we take data that has either been split from the initial set, or data that has been manually labelled and compare this with the data that our model has produced. The accuracey at which our model can predict or identify a particular set of data when compared to pre-labelled or split data is the base creteria for success when testing a model.
Deployment
The final step in the workflow, deployment involves the packaging of the current model iteration and it’s delivery to the various dependant services or teams. We may include the data produced from this model thoughout stages in further iterations of the work flow to either compare or train future iterations, models could be delivered to engineering teams that are integrating it into their solution, or if the model itself is a MLaaS a deployment of the model into a production environment.